
데이터 전처리
◈ 데이터 전처리는 무엇일까?
데이터 전처리는 데이터에 이상값을 찾아 분석하기 좋게 데이터를 고치는 모든 작업을 말합니다.
데이터에 이상값이 있을 때 데이터 분석 및 통계 모델링 결과에 영향을 주어 결과값이 크게 변경될 수 있습니다.
데이터 세트에서 이상값의 불리한 작용에는 다음과 같습니다.
- 오차 분산을 증가시키고 통계 검정의 검정력을 감소시킨다.
- 이상값이 무작위로 분포되지 않으면 정규성이 감소 할 수 있다.
- 실질적인 관심이 있는 추정치를 편향시키거나 영향을 줄 수 있다.
◈ 데이터 전처리 방법
1. 데이터 통합(Integration)
- 다양한 로그 파일 및 데이터베이스의 통합
- 일관성 있는 데이터 형태로 변환
2. 데이터 변환(Transformation)
- 정규화(nomalization)
# Min-Max Nomalization (최소-최대 정규화) : 모델에 투입될 모든 데이터 중에서 가장 작은 값을 0, 가장 큰 값을 1로 두고 나머지 값들은 0과 1 사이의 값으로 스케일링해주는 정규화기법입니다. Min-Max Nomalization에는 이상치 값에 취약하다는 단점이 있습니다. 정규화 과정을 거치기 전에 이상치 값을 찾아내어 삭제하거나 변환해주어야 합니다.
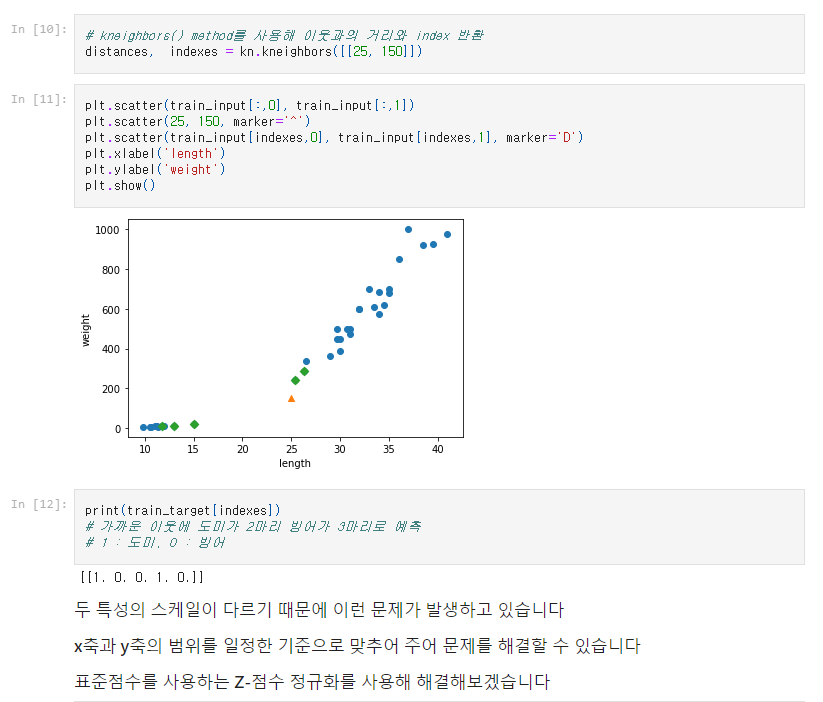
# Z-Score Nomalization (Z-점수 정규화) : X라는 값을 Z-점수로 바꿔주는 기법입니다. '(X - 평균) / 표준편차'를 통해 어떤 데이터가 표준 정규 분포에 해당하도록 값을 바꿔줍니다. 그래서 데이터 X가 평균값과 같다면 0으로 정규화되겠지만 평균보다 작으면 음수, 평균보다 크면 양수로 나타납니다. 이때 계산되는 음수와 양수의 크기는 표준편차에 의해 결정됩니다. 그래서 데이터의 표준편차가 크면 정규화 되는 값이 0에 가까워집니다.
- 집합화(aggregation)
- 요약(summarization)
3. 데이터 축소(Reduction)






github 코드 첨부
https://github.com/erdnussretono/K-Nearest-Neighbors_3/blob/main/KNN_3.ipynb
erdnussretono/K-Nearest-Neighbors_3
Contribute to erdnussretono/K-Nearest-Neighbors_3 development by creating an account on GitHub.
github.com
'AI' 카테고리의 다른 글
| [머신러닝] 선형회귀(Linear Regression) (0) | 2021.07.17 |
|---|---|
| KNN(K-Nearest Neighbors) 회귀(regression) (0) | 2021.07.17 |
| [데이터 전처리] titanic data 전처리 (0) | 2021.07.17 |
| [머신러닝 데이터] 훈련 세트와 테스트 세트 (0) | 2021.07.15 |
| KNN(K-Nearest Neighbors) 알고리즘 기본개념 (0) | 2021.07.14 |